Bloom Filter알고리즘과 Angular DI 성능 개선

Bloom Filter
Bloom Filter는 어떤 Set안에 특정 값이 존재하는지 여부를 빠르게 계산할 수 있는 알고리즘이다. 속도도 빠르면서 저장 공간을 적게 차지하기 때문에 대규모 서비스에서 신규회원 여부, 크롬 브라우저의 멀웨어 사이트 여부, hbase, redis 등 여러 군데에 활용되고 있다.
재미있는 점은 이 Bloom Filter 알고리즘은 확률적 자료 구조라는 점이다. 계산의 정확도가 100%가 아니다. False Positive Probability(이하 FPP) 즉 거짓을 반환할 확률이 있다. 정확도를 희생하고 메모리 사용량을 얻은 셈이다.
이 FPP는 0%가 될 순 없지만 일반적으로 알고리즘의 각 변수를 제어하여 0% 에 수렴하는 최적의 값을 찾아서 도입한다. 이에 관련한 자세한 내용은 뒤에서 다루고. 먼저 원리에 대해 간단히 설명한다.
동작 원리
이 알고리즘은 요소들이 담길 공간, 필터, 해시 함수가 필요하다. 공간은 앞서 언급한 대로 회원 DB등 특정 값이 존재하는지 검사할 집합이다. 필터는 0, 1을 표현할 수 있는 Bit의 배열이다. 해시 함수는 특정 값을 넣었을 때 항상 똑같은 길이의 값을 반환하는 함수를 말한다.
설명을 위해 공간은 문자열 배열, 필터는 6칸을 사용하고. 해시는 길이 6의 값을 출력하는 hashA, hashB 를 사용한다고 하자. 그리고 코드는 이해를 돕기 위해 비트를 나열한 수도 코드를 사용한다.
배열에 값 추가하기
먼저 배열에 요소를 추가할 땐 항상 해시함수 2개를 돌린 값을 OR 비트 연산하고 이를 필터와 OR연산하여 필터를 업데이트한다.
arr = []
filter = 000000
newValue = 'owl'
h1 = hashA(newValue) // 010000
h2 = hashB(newValue) // 001000
(filter |= h1) |= h2 // 011000
arr.push(newValue)요소 owl을 추가하여 필터 값은 011000이 되었다. 그리고 이어 값을 하나 더 추가한다.
newValue = 'hawk'
h1 = hashA(newValue) // 100000
h2 = hashB(newValue) // 000010
(filter |= h1) |= h2 // 111010
arr.push(newValue)이제 필터의 값은 111010이 되었다.
🍳 값 존재 여부 검사하기
이제 처음 추가한 owl이 존재하는지 여부를 검사해 보자.
checkValue = 'owl'
h1 = hashA(checkValue) // 010000
h2 = hashB(checkValue) // 001000
h = h1 | h2 // 011000
!!(filter & h) // 011000 => true해시 함수를 돌린 값 011000 과 현재 필터 값 111010을 AND연산하면 값은 011000으로 Boolean변환 시 true가 된다. 이 값은 배열에 존재할 확률이 높다. 다음은 존재하지 않는 값에 대한 검사이다.
checkValue = 'duck'
h1 = hashA(checkValue) // 000100
h2 = hashB(checkValue) // 000001
h = h1 | h2 // 000101
!!(filter & h) // 000000 => false해시 함수를 돌린 값 000101과 현재 필터 값 111010을 AND연산하면 값은 000000이므로 Boolean변환 시 false가 된다. 이 값은 배열에 존재하지 않는다. 👀 여기까지 따라왔다면 중요한 문제인 다음 예제를 보자.
checkValue = 'crow'
h1 = hashA(checkValue) // 001000
h2 = hashB(checkValue) // 000010
h = h1 | h2 // 001010
!!(filter & h) // 001010 => true값 **‘crow’**는 배열에 없지만 해시 값은 001010이므로 연산 결과에서 true가 나왔다. 이것이 바로 Bloom Filter의 FPP특성. 없는 값을 있는 것으로 계산할 수 있는 특성이다. 이런 특성에도 불구하고 이 알고리즘 사용하는 이유는 메모리 사용량이 적다는 점 때문이다.
일반적으로 배열에 특정 값이 존재하는지 빠르게 찾기 위해서 값을 키로 갖는 객체를 만들어 사용한다. 해당 객체 안에 키 값이 있다면 배열 내에 값이 존재하는 것이다. 이 경우 객체외 키의 갯수만큼의 메모리 공간을 더 사용해야 한다. 하지만 예제의 필터에서는 6칸의 배열만 필요했다. 실무에서도 256길이의 필터면 대 부분 해결되는 수준이다.
혹시 위에 언급하는 예제를 데모로 보고 싶다면 Bloom Filters by Example을 참고하기 바란다.
실제로 서비스에 적용할 땐. 이 FPP를 0%에 근접하도록 각 변수의 값을 계산해 적용한다. 위의 예제에서 바꾼다면 필터의 길이를 256과 같이 매우 길게 하고. 해시 함수도 20개 이상으로 많이 사용하면 정확도가 올라갈 것이다. 계산식도 나와 있는데 Bloom Filter 사이즈 계산기에서 확인해 볼 수 있다.
요소에 들어가는 아이템의 개수 (n), 원하는 FPP값(p), 필터의 비트 개수(m), **해시 함수의 개수(k)**를 부분적으로 입력하면 입력하지 않은 변수의 최적의 값을 뽑아 준다.
Bloom Filter는 Backend뿐만 아니라 Frontend에서도 얼마든지 사용할 수 있다. 해시 함수의 정확도나 비용을 고려했을 때는 대량의 데이터를 다루긴 어려울 수 있지만. 웹어셈블리를 활용한다면 이 제약도 없다.
Angular의 Bloom Filter
로직 설명은 Angular DI: Getting to know the Ivy NodeInjector 에 상세히 나와 있다. 그런데 글이 조금 어려워서 알기 쉽게 풀어 설명해 본다.
⚠ 예제는 Angular v8.3.28 기준이다.
Angular는 v8버전부터 Ivy Renderer가 추가되면서 대대적인 성능 향상 작업이 이루어졌다. 그 수 많은 개선사항 중 Bloom Filter는 NodeInjector에서 특정 Provider의 존재 여부를 검사하는 로직에 적용되어 있다.
Ivy가 템플릿 렌더링에 사용하는 IncrementalDOM은 전통적으로 사용하던 VirtualDOM 에 비해 메모리 사용량이 적다는 특징이 있는데. Bloom Filter 알고리즘도 메모리 사용량이 적으므로 시너지가 있을 것으로 보인다.
Angular는 아래 코드처럼 특정 Component의 생성자에 특정 타입의 파라미터를 추가하면. 런타임에 알아서 타입에 맞는 의존 인스턴스를 찾아 없으면 만들어서 주고 있으면 주는 DI 시스템이 있다.
// PARENT
@Component({
template: `<app-hello></app-hello>`,
})
class AppComponent {}
// CHILD
@Component({
selector: 'app-hello',
})
class HelloComponent {
// AppComponent 를 생성자에서 주입받고 있다
constructor(private app: AppComponent) {}
}위 코드에서 HelloComponent는 자신을 그린 상위 컴포넌트 AppComponent를 DI받고 있다(생성자에 같은 타입의 파라미터를 기입함). 따라서 HelloComponent는 인스턴스 생성 시점에 첫 번째 인자로 AppComponent의 인스턴스를 받을 수 있다.
이 때 AppComponent타입의 인스턴스를 찾기 위해 Angular내부적으로 먼저 NodeInjector를 거슬러 올라가며 찾고 찾지 못하면 이어 ModuleInjector를 찾아 올라가는 동작을 하게 된다.
이 중 NodeInjector는 Component들의 계층 구조에서 bootstrap된 최 상위 컴포넌트 까지 마치 DOM트리에서 버블링이 일어나는 것 처럼 각 Component마다의 providers, viewProviders를 살펴본다.
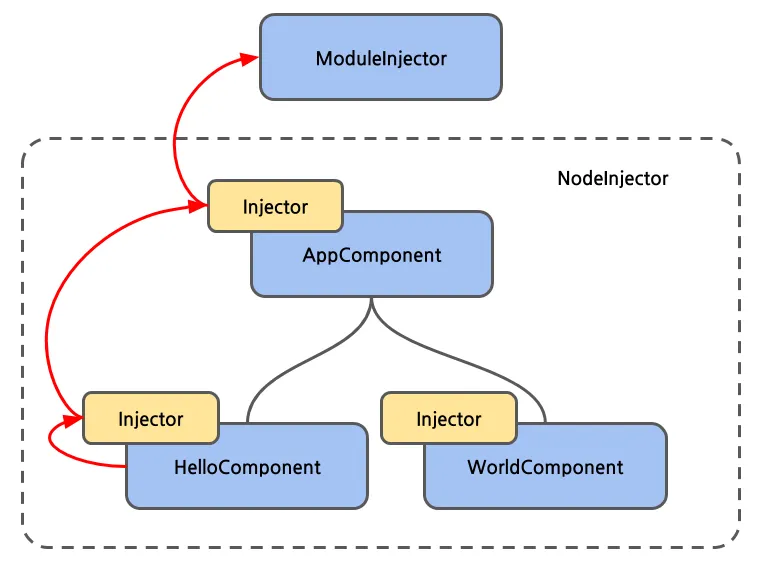
이 때 Component의 메타데이터에 설정한 배열을 직접 살피는 게 아니라. 각 노드에 있는 Injector 인스턴스에게 특정 타입으로 생성된 인스턴스가 있는지 묻게 된다. 바로 이 과정에서 Bloom Filter를 사용한다.
아래 코드는 해시와 필터를 AND연산하여 존재 유무를 판별하는 로직을 가져와서 조금 해석해 보았다.
export function bloomHasToken(
// 컴포넌트 ID의 해시 값 (입력값)
// 위의 데모 코드에서 AppComponent는 처음으로 처리되기에 값이 0이다.
// 따지고 보면 Provider의 종류가 공식에서 (n)이 된다.
bloomHash: number,
// JS의 비트연산은 32비트라 256짜리 필터를 담을 수 없어 필터를 32비트씩 8개로 쪼갠 것으로 보인다
injectorIndex: number,
// 순수함수라 배열을 세 번째 인자로 넘기고 있다
injectorView: LView | TData
) {
// Create a mask that targets the specific bit associated with the directive we're looking for.
// JS bit operations are 32 bits, so this will be a number between 2^0 and 2^31, corresponding
// to bit positions 0 - 31 in a 32 bit integer.
const mask = 1 << bloomHash
const b7 = bloomHash & 0x80
const b6 = bloomHash & 0x40
const b5 = bloomHash & 0x20
// Our bloom filter size is 256 bits, which is eight 32-bit bloom filter buckets:
// bf0 = [0 - 31], bf1 = [32 - 63], bf2 = [64 - 95], bf3 = [96 - 127], etc.
// Get the bloom filter value from the appropriate bucket based on the directive's bloomBit.
let value: number
// 8개 필터를 모두 사용하는 것이 아니라. 위에서 만든 플래그 기준으로
// 어떤 것을 써야 하는지 분기하고 있다. 즉 실제로 사용하는 필터 자체는 32비트이다.
if (b7) {
value = b6
? b5
? injectorView[injectorIndex + 7]
: injectorView[injectorIndex + 6]
: b5
? injectorView[injectorIndex + 5]
: injectorView[injectorIndex + 4]
} else {
value = b6
? b5
? injectorView[injectorIndex + 3]
: injectorView[injectorIndex + 2]
: b5
? injectorView[injectorIndex + 1]
: injectorView[injectorIndex]
}
// 앞서 공부했던 대로 AND연산하여 존재 여부를 확인하고 있다.
// If the bloom filter value has the bit corresponding to the directive's bloomBit flipped on,
// this injector is a potential match.
return !!(value & mask)
}